[Alcuin, a librarian of the Carolingian Renaissance and advisor to Charlemenge, recently interviewed for a data librarian position, and below is a transcript of some of the interview with the search committee. --ELM]
The Boss: Mr. Alcuin, it is very nice to meet you. You have quite an impressive resume, and we are honored that you have selected our library as a possible place of employment.
Alcuin: Thank you, thank you very much. It is a pleasure and an honor to be here too.
The Boss: Your welcome. Now, the committee has a few questions we'd like ask. Please bare in mind, there are zero right or wrong answers. Instead, the questions are intended to help us guage whether or not you are a good fit for our organization and the work you may be doing here. Put another way, just like the librarian who knows about printing, publishing, and binding will be knowledgeable about the curation of physical collections, the librarian who knows about data ought be able to curate digital collections. We would like to garner your opinion and experience on such things.
Alcuin: I completely understand.
The Boss: Ranganathan, will you please begin?
Ranganathan: Sure, no problem. Thank you.
[Ranganathan paused in his usual reflective way.]
Ranganathan: Alcuin, what is data, and how is it different from information, knowledge, and wisdom?
Alcuin: A very interesting question, and ironically, I often think about such things. At its core, data is comprised of numbers and strings, where numbers are the things of mathematics, and strings are everything else, usually words. Information is data given context. For example, a number is 1776, but when it is associated with the idea of a year, then the number takes on a meaning. Knowledge is information understood and put to use. For example, we might say, "In the year 1776, a new form of government was drafted, and that government has lasted about 250 years." Wisdom can be characterized as knowledge of a timeless nature, but such is the purview of epistemologists, not necessarily librarians.
Ranganathan: Very philosophical. Thank you. On a more down-to-earth level, please enumerate seven or eight different file-based data structures that you have used in your work.
Alcuin: Yes, data must be manifested, and there are quite a number of different forms such manifestations can take. I often use everything from line-delimited lists to comma-separated value files, from MARC records to relational databases, and from XML to JSON, not to mention different instantiations of RDF. A great deal of my time is spent simply transforming data from one manifestation into another. I try very hard to stay away from Excel. Excel is not a data structure; Excel is an application.
Mr. Cutter: What are some of the ways the file types can be compared and contrasted?
Alcuin: TSV, CSV, and Excel files are two-dimensional (flat), easy for most people get their heads around, very common, and load into just about any spreadsheet or database program. On the other hand, things like carriage returns and newlines embedded in cells will break the data structures. TSV and CSV files are operating system independent, but one pretty much needs Excel or a special Excel reader to use an Excel file. Relational databases are n-dimensional (not flat) and therefore can easily handle one-to-many relationships. Relational databases also support a standard query language, and some of the most powerful queries employ the GROUP command, which enables one to easily count and tabulate things. XML is considered expressive, but at the same time, verbose; it is designed to be human-readable. There are all sorts of ways to determine whether an XML file/stream is syntactically correct (well-formed) as well as semantically correct (valid).
[Everybody took notes.]
Alcuin: JSON is often seen as the more modern version of XML, but it does not support comments, nor are their ways to denote whether or not its content is semantically correct. On the other hand, it is terse and therefore lends itself to HTTP transmission. JSON is an inherent part of JavaScript, and has made its way into every other programming language. Also, a JSON stream can include more rudimentary data structures such as name-value pairs, key-value pairs, lists (arrays), etc. MARC is the primary bibliographic data structure used here in Library Land. Ubiquity is its strength, and its greatest weakness is that it conflates library business logic with the data.
[Mr. Cutter, Mr. Dewey, and Ms. Avery squirmed in their chairs.]
Alcuin: For example, unless one knows things like, "We here at our library put this code into that field to denote such and such", then interpreting MARC is problematic. Because of its age, MARC also suffers from encoding errors; not only are all records not encoded in ASCII, but they are not encoded in UTF-8 either.
Mr. Cutter: Do you know what an entity relationship diagram is, and can can you draw one illustrating the bibliographic elements of a book with authors, titles, dates, call numbers, and subjects?
Alcuin: Certainly.
[Alcuin drew the following diagram.]
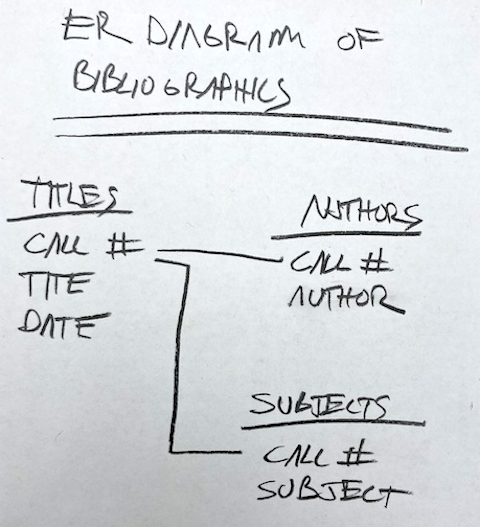
Ms. Avery: Similarly, how might you serialize the same bibliographic information as a CSV, JSON, or XML file?
Alcuin: Serializing bibliographic data in the form of CSV, or any matrix-like data structure, is problematic because of the one-to-many relationships inherent in bibliography. For eample, an item may have many authors or many subjects, thus necessitating the need for something I call "syntactical sugar" embedded in column values. Very ugly. If I were to serialize bibliographic data in the form of XML, then I'd lean towards MODS and maybe MARCXML. While the Library of Congress designed MARCXML to be "roundtripable" with MARC, MODS is more human-readable and supports more robust validation. JSON is nice, but since JSON does not really support validation, I'd stick with XML.
Mr. Naude: What is the difference between a Linux/Macintosh-based and a Windows-based plain text file?
Alcuin: The answer is rooted in the mechanics of typewriters. Remember those? The typewriter includes a part called the platen which is moved back and forth on a carriage. As the carriage moves from right to left, the operator needs to return the carriage to the right-most position before coming to the right-most edge of the paper. This operation requires two motions: 1) moving the carriage (and thus the paper) all the way to the right, and 2) spinning the carriage up one line so new lines are not superimposed on previous lines. These two motions are encoded in the ASCII character set as character 13 (carriage return) and character 10 (new line), and when text files are created one must delimit lines with some sort of character. Windows-based text files are delimited with carriage-return/new-line character combinations. Linux text files are delimited by new line characters. Older Macintosh text files were delimited with carriage returns characters, but now-a-days they are delimited in the same way as Linux files. Thus, the text files of different operating systems have different line endings, and it is very important to normalize these values before doing any processing against them. Incidentally, the tab character (ASCII character 9) is very interesting in its own regard...
[The Boss interrupted.]
The Boss: Thank you Mr. Alcuin. That is quite enough, but I am impressed. A great deal of the way we use computers now-a-days is rooted in older technology. Many people do not appreciate such nuances.
Alcuin: I apologize. I got a bit carried away.
[Everybody chuckles, a bit nervously.]
Ms. Avery: Myself, as a person who has an invested interest in dissemination, please tell me. What are some common Internet protocols used for disseminating and sharing data?
Alcuin: There are quite a number, each with its own strengths and weaknesses. I am familiar with the venerable Z39.50, a stateful protocol specifically designed with bibliographics in mind. Now-a-days, HTTP is the protocol most often used, and many more specific protocols have been built on top of it. One of the oldest but least used is called SOAP and it exploits the features of XML. OAI-PMH is also about XML over HTTP, and it is a very stable protocol, in that it has not evolved. The original developers of OAI-PMH had high hopes for its implementation but got frustrated with the lack of adoption. Ironically, it is still used -- quite effectively I might add -- in open access journal publishing and institutional repository systems.
[More notes were taken.]
Alcuin: RSS and ATOM, again rooted in XML over HTTP, are used to syndicate HTML content such as blog postings, but the process of blogging is fading. All that said, REST-ful protocols are the most common. Again, built on top of HTTP, REST-ful protocols most commonly transmit name-values pairs in the form of URLs. HTTP clients and servers use these name-value pairs as inputs to applications and return results accordingly. In short, now-a-days it is all about HTTP. Thoroughly understand HTTP and the world of data and information is your oyster.
Mr. Dewey: What is Linked Data, and how can it be used in Library Land?
Alcuin: Linked Data is a manifestation of the Semantic Web. It is a process of denoting relationships between things in the form of triples, where each triple is a subject-predicate-object combination. Ideally, the subjects, predicates, and objects are manifested as actionable URIs shared across a given domain. The items in library collections can be described using triples. For example, [Huck Finn][has author][Mark Twain], or [Huck Finn][has date][1855]. Given enough assertions, it is trivial to discover what other items [has author][Mark Twain] and if any of them [has date][1855]. If libraries were to make their catalogs available as Linked Data, then additional, non-library related knowledge can be associated with collections such a maps illustrating where books were published, biographies and images of authors, or timelines illustrating co-occurring events. Linked Data provides the means of adding context to library collections, thus transforming library information into knowledge.
Mr. Cutter: Data types and data formats are often conflated. Please help me understand the difference.
Alcuin: The conflation is rooted in the difference between files and information. We have PDF files, Word files, CSV files, XML files, MPEG files, HTML files, etc. On the other hand, we have magazine articles, scholarly journal articles, survey results, data sets, music, books, book chapters, blog postings, government reports, speechs, plays, etc. The later can be manifested as PDF files, Word files, or CSV files, but not the other way around. This confation infects collection development policies because our profession do not often enough distinguish the difference between formats and types. Dubin Core does not help the situtation. There are Dublin Core formats (mime-types), and Dublin Core types which are things like books, articles, sound recordings, etc.
[Alcuin sighed.]
Mr. Dewey: Given a set of data, how might you go about indexing it?
Alcuin: The process is interative: 1) getting the data, 2) organizing it on a file system, 3) optionally importing it into some sort of database application, 4) applying a technology such as SQL, Solr, or ElasticSearch to Steps #2 or #3, 5) creating an interface to supply input and get output from Step #4, and 6) returning to Step #1. The process is never done. By the way, if you implement a Solr index, make sure it is behind some sort of authentication mechanism, because if you don't, then a single URL sent to the index by anybody in the world can wipe out -- delete -- the whole thing.
[Everybody raised their eyebrows.]
Ranganathan: What is librarianship, and considering the advent of the Internet, how has librarianship changed? With these things in mind, what is "data librarianship", and what are some of the roles of institutional repositories? Moreover, how might the implementation of an institutional repository be deemed successful?
Alcuin: Librarianship is about the collection, organiation, preservation, and dissemination of data, information, and knowledge...
[The Boss interupted.]
The Boss: Ranganathan and Alcuin, I'm sorry, but we've run out of time. I hope we can discuss these things in greater detail over dinner. Until that time, Alcuin, thank you coming by. We will reflect on our interview and get back to you in due course.
Alcuin: Thank you for your time, and thank you for the opportunity to share some of my ideas.